Introduction
Earlier this year, our Kubernetes infrastructure reached a tipping point. What started as a convenient autoscaling solution—Karpenter—had evolved into a source of operational chaos. Our nodes were constantly cycling, disks frequently hit pressure limits, and our costs were spiraling out of control. It became clear: we needed a fresh start.
This is the story of how we successfully migrated from Karpenter (v0.34.5) to Cluster Autoscaler, reducing our daily node churn by more than 95%, eliminating disk pressure problems, and drastically cutting our AWS bills.
The Problem with Our Old Karpenter Setup
Our Kubernetes clusters were running on EKS v1.29, supported by an outdated Karpenter installation. Over time, several critical issues surfaced:
1. Excessive Node Churn
We noticed an alarming pattern: every single day, Karpenter created and deleted more than 900 nodes, as illustrated below:
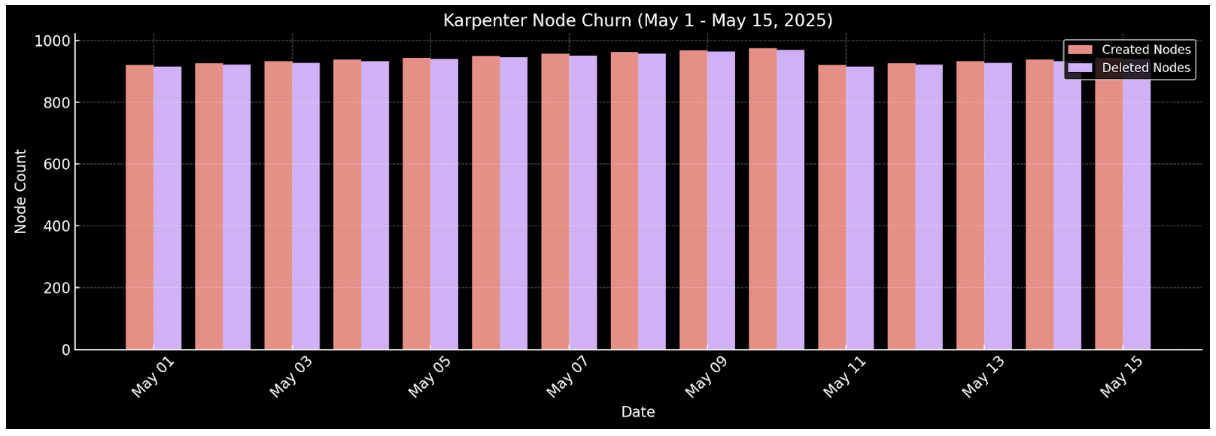
This graph represents a typical two-week window in May 2025, clearly highlighting the instability we faced.
This constant cycling:
- Increased resource overhead
- Caused unnecessary pod evictions
- Spiked our AWS costs significantly
Please find below the costing graph as well for the same timeframe:
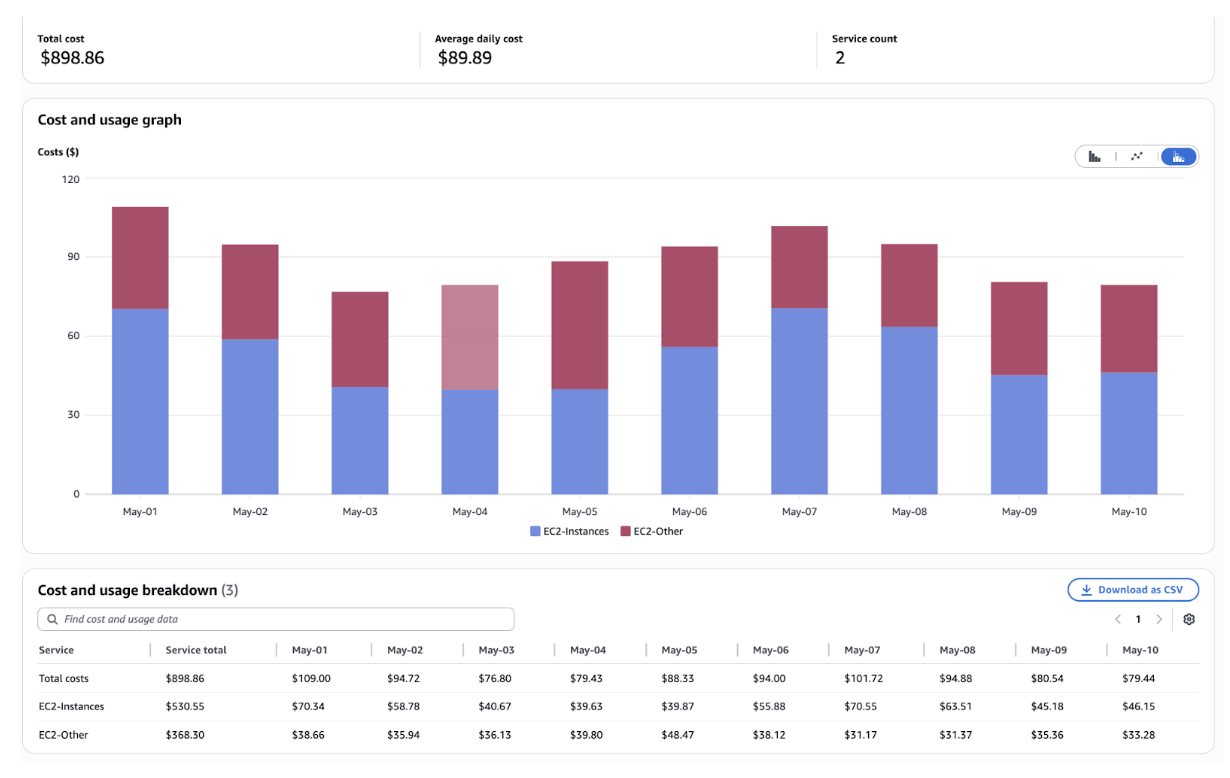
Costing graph showing the financial impact of excessive node churn
2. Disk Pressure and Inefficient EBS Usage
Nodes were provisioned with a fixed 100GB EBS volume regardless of instance type. Consequently:
- Smaller nodes wasted disk space, inflating costs.
- Larger nodes frequently experienced disk pressure issues.
- Managing disk alerts became a routine firefighting activity for our team.
3. Complex and Rigid Node Configurations
The lack of fine-grained control over instance types, especially distinguishing Spot vs. On-Demand instances, created unpredictable behavior. We couldn't prioritize newer generation instances effectively, causing us to miss out on cost-saving opportunities.
Our Migration Approach: A Fresh Start
Instead of incrementally upgrading our existing infrastructure—which would have introduced significant risk—we chose a clean-slate approach:
- Provisioned a brand-new EKS cluster
- Implemented Cluster Autoscaler
- Executed a lift-and-shift migration to quickly move workloads without disruption
Key Changes and Configurations
We adopted several strategies that dramatically improved our Kubernetes cluster:
1. Standardized Node Sizes (2xlarge Instances)
We standardized our instance size to 2xlarge across all nodes, aligning perfectly with a consistent 100GB EBS volume. This solved our disk pressure issues overnight:
- Smaller nodes no longer wasted disk capacity.
- Larger nodes had sufficient space, eliminating frequent disk alerts.
2. Cluster Autoscaler with Priority Expander
We implemented a sophisticated priority expander configuration, intelligently selecting optimal Spot instances:
100:
- ".*m8g.*SPOT.*"
- ".*c8g.*SPOT.*"
- ".*r8g.*SPOT.*"
99:
- ".*t3a.*SPOT.*"
...
1:
- ".*"This prioritization ensured we always used the most cost-effective, performant instances available, with automatic fallback options if necessary.
3. Overprovisioning with Least Priority Class
We introduced a least-priority class with cluster-wide overprovisioning to always ensure spare capacity for rapid pod scaling, significantly improving pod startup latency and reliability.
Results: Stability and Cost Savings
The impact of this migration was transformative. The daily node churn dropped dramatically, and we achieved significant operational and financial improvements:
Node Churn Comparison
The graph below shows the drastic reduction in node churn post-migration in June 2025:
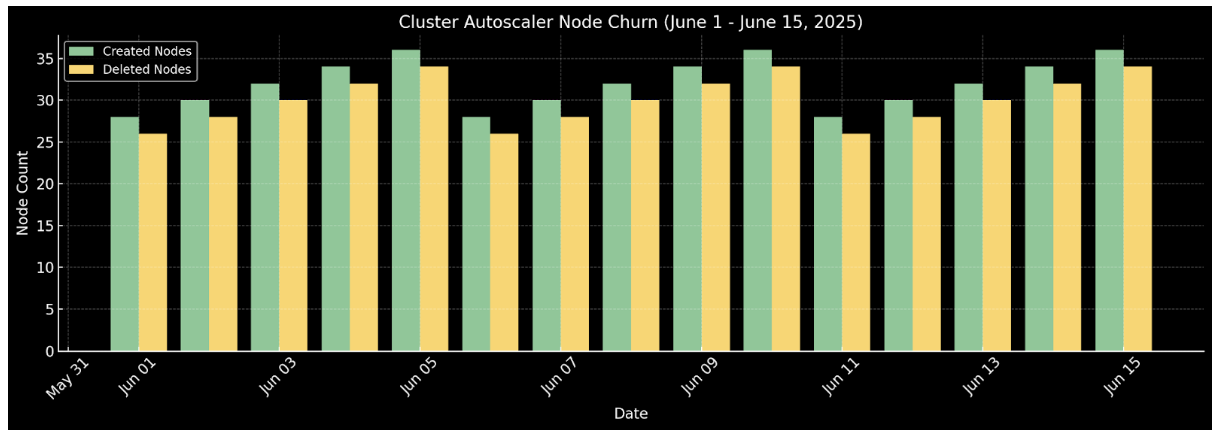
Dramatic reduction in node churn after migration to Cluster Autoscaler
Please find below the costing data post migration clearly showing around 50% reduction in cost:
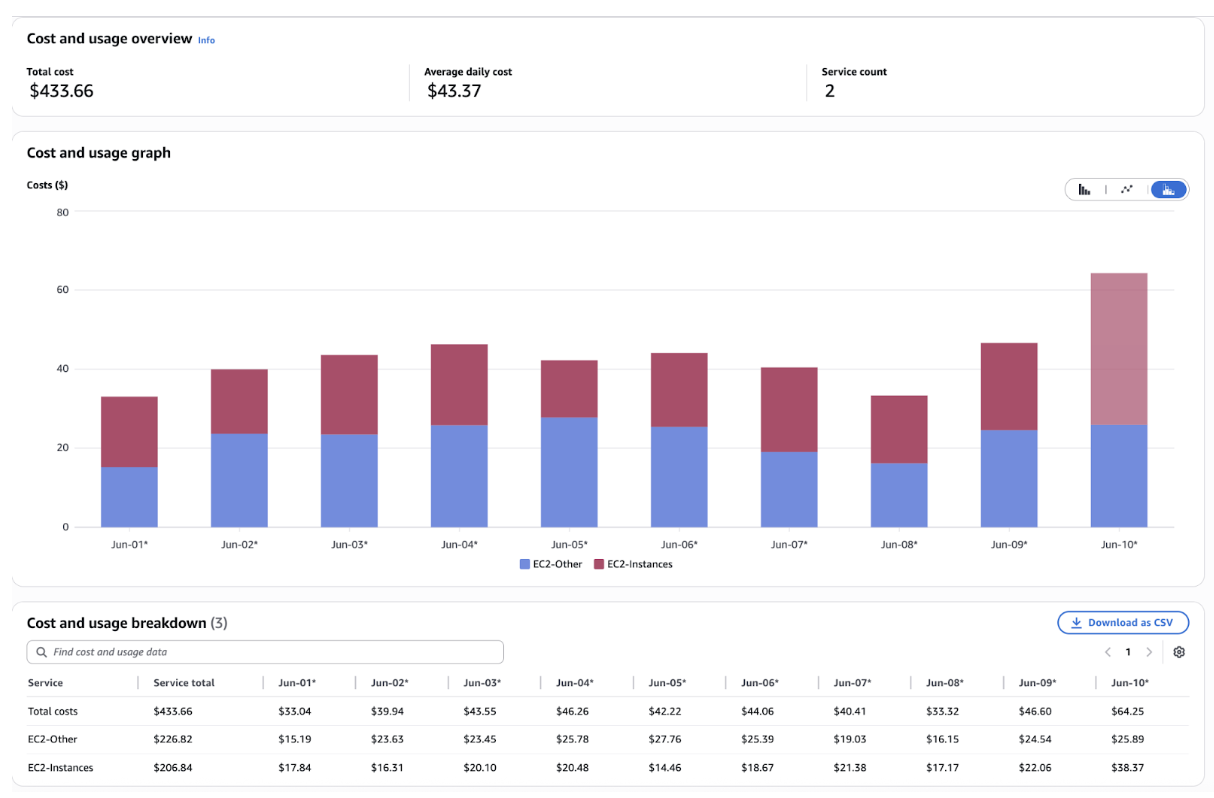
Cost reduction graph showing 50% savings after migration
| Metric | Before (Karpenter) | After (Cluster Autoscaler) |
|---|---|---|
| Daily Node Churn | 900+ nodes/day | ~30 nodes/day |
| Disk Pressure | Frequent | Completely Eliminated |
| EBS Costs | High | Significantly Reduced |
| Application Uptime | Unstable | Highly Stable |
Lessons Learned
The migration wasn't just about replacing one autoscaler with another. It underscored critical infrastructure lessons:
- Consistency Matters: Standardized infrastructure reduces complexity and surprises.
- Intelligent Automation Beats Reactive Scaling: Thoughtful prioritization and overprovisioning can eliminate most scaling emergencies.
- Sometimes, a Clean Slate is Best: Building a parallel cluster is safer and more efficient than incremental upgrades when managing legacy infrastructure.
Conclusion
Switching to Cluster Autoscaler stabilized our Kubernetes clusters dramatically. The significant reduction in daily node churn, complete elimination of disk pressure alerts, and optimized costs have enabled us to focus on delivering value rather than fighting fires.
This migration not only stabilized our infrastructure but also made a strong case for taking bold, decisive action when legacy systems start to become operational liabilities.

