1. Introduction: When Redis Became the Bottleneck
Redis is well known for its ultra-low latency and high throughput, making it an ideal fit for use cases such as caching, session state management, real-time analytics, and pub/sub queues. In our system, Redis played a critical role and was deployed on AWS EC2 for cost control and flexibility — specifically on an r6g.xlarge instance with a 200 GB gp3 EBS volume and 3000 IOPS.
This setup worked well for many months. However, one day, a major spike in traffic exposed a serious weakness in our deployment:
- Background persistence (BGSAVE) operations began overlapping and saturating disk I/O.
- The Redis process became slow to respond, causing application latency to increase.
- Eventually, we observed persistence errors (BGSAVE failures) and potential data loss.
In this case study, I'll walk through:
- How we diagnosed the issue using Grafana and Redis Exporter
- How we reproduced the problem using controlled load tests
- Why we migrated to Amazon ElastiCache (OSS Redis 7.1.0)
- How we used Redis-Shake and a dual-write strategy to minimize downtime
2. The Problem: Redis Struggled with Persistence and Latency
2.1 Initial Setup
- EC2 instance: r6g.xlarge (4 vCPUs, 32 GB RAM)
- Disk: 200 GB gp3 EBS (3000 baseline IOPS)
- Redis version: 7.1.0
- AOF: Disabled
- Eviction policy: No eviction
- Snapshot save policy:
- save 1800 1 (1 key in 30 min)
- save 900 2000 (2000 keys in 15 min)
- save 300 10000 (10,000 keys in 5 min)
With millions of operations per minute, these thresholds were constantly exceeded, triggering frequent snapshots. Each snapshot (BGSAVE) uses fork(), which is CPU and disk-intensive—especially with 200 GB of memory in use.
2.2 Symptoms During Production Spike
- Memory usage exceeded 199 GB
- Redis was stuck in BGSAVE state, failing to complete saves
- Logs showed snapshot failures
Key metrics:
- used_memory: 214.5 GB
- used_memory_dataset_perc: 98.6%
- rdb_bgsave_in_progress: 1
- rdb_last_bgsave_status: err
- rdb_last_bgsave_time_sec: 706
This indicated that save operations were taking upwards of 10 minutes and often failing. At the same time, Redis continued serving live traffic, making the system unstable and vulnerable to data loss.
Key technical observation:
- Redis snapshotting (RDB) uses fork(), and when memory exceeds 100 GB, copy-on-write (COW) cost becomes significant.
- BGSAVE causes memory fragmentation and disk write spikes, and EC2 disks like gp3 are not always fast enough to keep up.
(Reference: https://redis.io/docs/management/persistence/#snapshotting)
3. Reproducing the Issue via Load Tests
To validate our suspicions and quantify the impact, we cloned the EC2 Redis setup and simulated real-world traffic via controlled load tests.
Load Test Configuration:
- 200 Virtual Users (VUs)
- 100,000 to 150,000 requests per minute
- Duration: 5 minutes
- Mix: 80% SET, 20% GET operations
- Redis Exporter + Grafana to monitor live performance
What we observed:
- The EC2 Redis instance began struggling once memory usage exceeded ~180 GB.
- Snapshot times increased significantly, often overlapping with ongoing writes.
- Ops/sec dropped, latency spiked, and cache hit ratios dropped.
4. Moving to Amazon ElastiCache: Performance Without the Headaches 🚀
After validating that our EC2-hosted Redis was failing under pressure, we evaluated three options:
- Tuning the EC2 Redis save policy
- Vertical scaling (bigger instance) and faster disk
- Switching to Amazon ElastiCache (Redis OSS mode)
We chose Option 3: ElastiCache, because it offered:
- A fully managed, highly available Redis environment
- Lower operational overhead (no OS/disk tuning needed)
- Tuned persistence behavior with better memory handling
- Seamless integration with CloudWatch and AWS IAM
4.1 ElastiCache Configuration
- Engine: Redis OSS 7.1.0
- Instance Type: cache.r6g.xlarge (same class as EC2)
- Replication: None (single node)
- Cluster Mode: Disabled
- AOF: Disabled (same as EC2 Redis)
- Eviction Policy: No eviction
- Parameter Group: Default
- Snapshotting: Enabled with optimized save policy
4.2 Updated Save Policy
To strike a better balance between data durability and performance, we changed the Redis save directive to:
- save 900 1
- save 300 10
- save 60
This configuration reduces snapshot frequency while still ensuring regular persistence of changes.
4.3 ElastiCache Load Test Results
Running the same 5-minute load test (200 VU, 150k ops) showed clear improvements:
- Commands/sec doubled to ~8,000
- RDB snapshot time dropped from ~160 seconds to ~20 seconds
- No errors or background save interruptions
- CPU and memory pressure remained well within limits
| Metric | EC2 Redis | ElastiCache |
|---|---|---|
| Avg ops/sec | ~4,000 | ~8,000 |
| Cache hit ratio | 0.75 | 0.90 |
| Snapshot time | ~160 sec | ~20 sec |
| 99th percentile latency | >300 ms | <50 ms |
This confirmed that ElastiCache's optimizations (dedicated hardware, memory-tuned OS, faster disks) made a significant difference.
Key points:
- Redis bgsave is safe but expensive under large datasets
- EC2 lacks the tuning and stability of a managed service
- ElastiCache provided 2x the throughput and much better tail latency
(Reference: https://redis.io/docs/reference/optimization/persistence/#latency-during-bgsave)
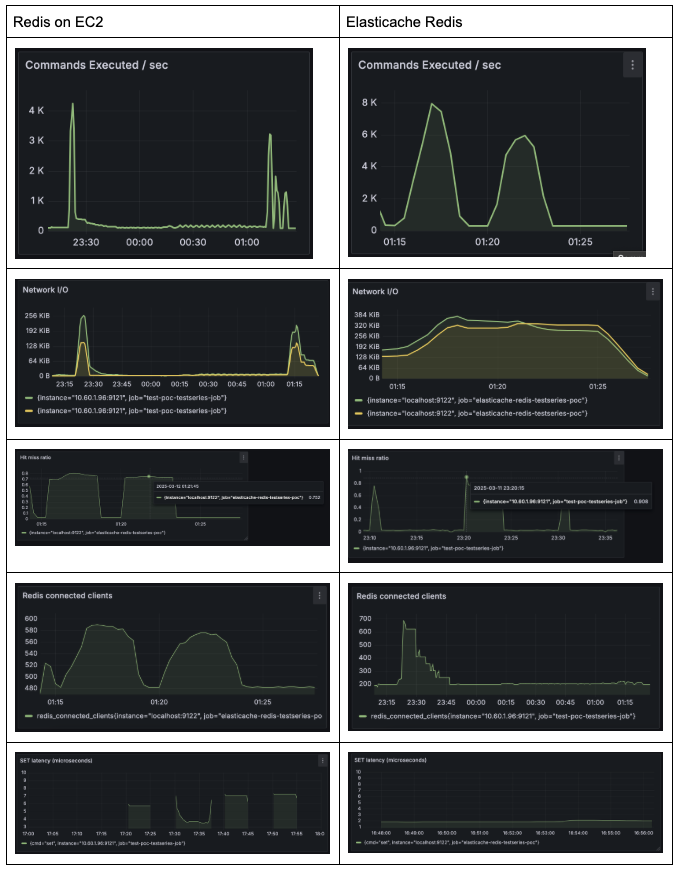
Redis on EC2 vs ElastiCache Redis performance comparison
Conclusion: The results suggest that ElastiCache is slightly more optimized to handle high traffic scenarios than EC2 Redis
- Performance: ElastiCache Redis outperforms EC2 Redis, handling 2x more commands per second (8K vs. 4K).
- Efficiency: ElastiCache shows a higher cache hit ratio (0.9 vs. 0.75), improving data retrieval speed and reducing database load.
- Optimization: AWS ElastiCache is optimized for Redis, benefiting from better performance, memory tuning, and managed optimizations.
- Operational Overhead: ElastiCache offers fully managed services with built-in failover and scaling, reducing manual effort compared to EC2.
Why ElastiCache Performed Better
- Memory overcommit handling is optimized in AWS Redis nodes
- Kernel-level tuning reduces latency during fork
- IO is better isolated from noisy neighbors (dedicated infra)
- AWS engineers fine-tune Redis process lifecycles under the hood
This confirmed that ElastiCache was the right target for migration.
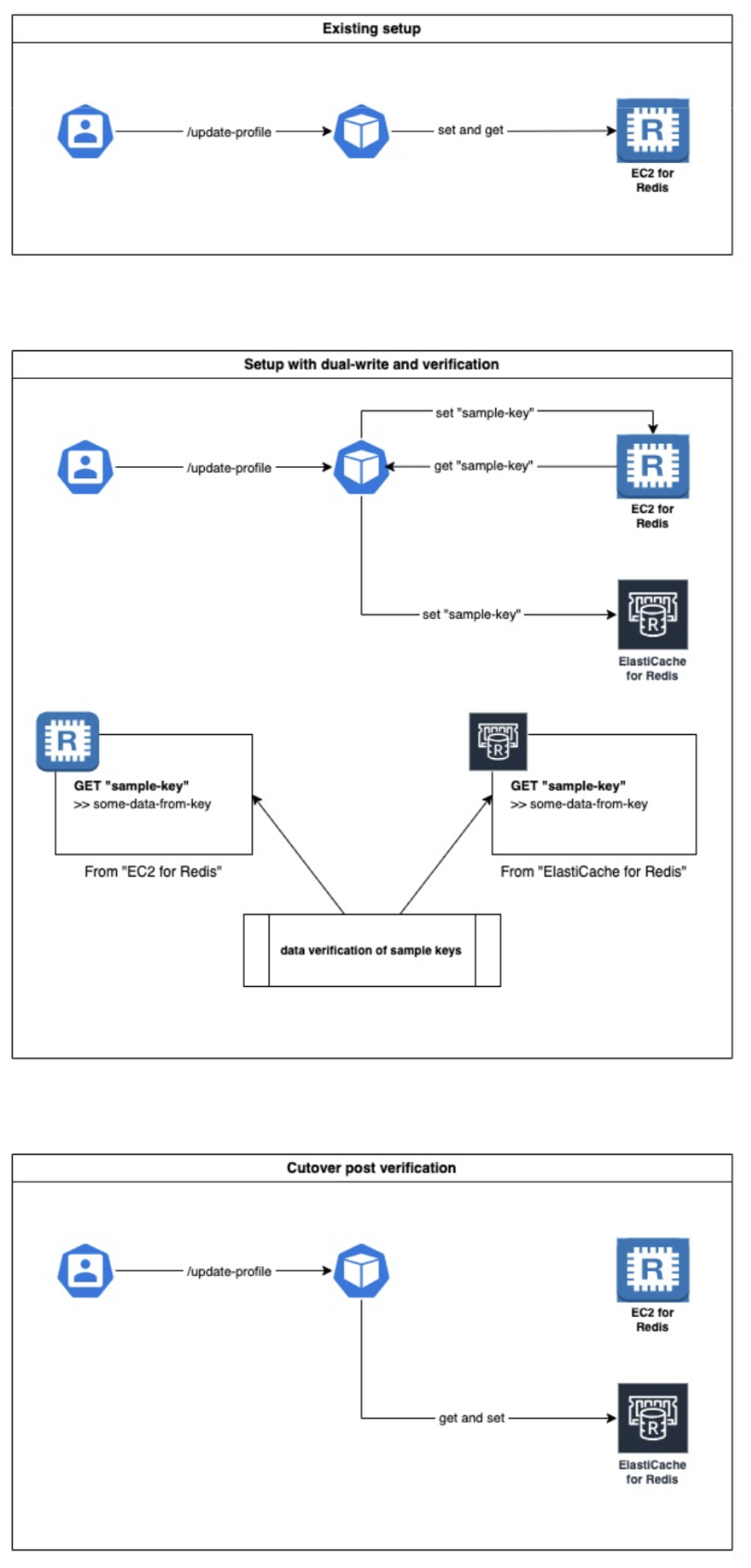
5. Seamless Migration with Redis-Shake and Dual Write
A key goal for us was to avoid downtime and ensure rollback capability during migration. We adopted a two-pronged strategy:
- One-shot key migration using Redis-Shake
- Application-level dual-write until confident in ElastiCache
5.1 Redis-Shake: One-Time Data Migration
We used Redis-Shake, an open-source tool by Alibaba, to migrate existing keys from EC2 Redis to ElastiCache.
Redis-Shake Features:
- Supports full + incremental sync
- High performance (multi-threaded)
- Easy to set up for standalone Redis clusters
Redis-Shake Setup:
[sync_reader]
type = "sync"
address = "127.0.0.1:6379"
cluster = false
[filter]
allow_db = [2, 5] # Only migrating DBs 2 and 5
[redis_writer]
type = "standalone"
address = "storefront-redis.unt198.ng.0001.aps1.cache.amazonaws.com:6379"
[advanced]
log_level = "info"
log_file = "redis-shake.log"Execution Flow:
git clone https://github.com/tair-opensource/RedisShake
cd RedisShake
sh build.sh
cd bin
./redis-shake config.tomlThis copied all keys from EC2 to ElastiCache in a few minutes without errors. Logs were monitored in real-time using screen.
5.2 Dual-Write Logic in Application
To protect against data inconsistency or hidden bugs, we enabled dual-write in the app layer:
- All SET/DEL operations were sent to both Redis nodes (EC2 and ElastiCache)
- All GET operations were redirected to ElastiCache
- Write failures were logged, but did not block reads
- Redis health checks were added to catch silent failures
This gave us time to:
- Validate live data behavior
- Compare key count, memory use, and TTLs
- Ensure functional parity
We ran in dual-write mode for several days, monitoring metrics and verifying correctness through:
- Redis memory usage (info memory)
- Ops/sec on both Redis servers
- Alerts via Grafana/Prometheus for any anomalies
Dual-write monitoring dashboard showing Redis performance metrics
5.3 Final Cutover and Decommissioning
Once confident:
- Dual-write logic was removed from the app
- All writes and reads switched fully to ElastiCache
- EC2 Redis instance was gracefully stopped after backup
- DNS/pipeline references were cleaned up
Conclusion: Future-Proofing Our Redis Architecture
Our journey from a self-managed Redis instance on EC2 to a fully managed Amazon ElastiCache solution was both enlightening and rewarding. We learned firsthand how operational bottlenecks—especially around persistence and resource limits—can threaten the reliability of even the most robust caching layers.
By leveraging ElastiCache, we not only resolved our immediate performance and stability issues but also unlocked a platform that scales effortlessly with our needs. The migration process, powered by tools like Redis-Shake and a careful dual-write strategy, ensured a seamless transition with zero downtime and no data loss.
Key Takeaways:
- Proactive monitoring and load testing are essential for uncovering hidden bottlenecks.
- Managed services like ElastiCache offer significant operational and performance benefits for mission-critical workloads.
- A well-planned migration strategy minimizes risk and ensures business continuity.
As our systems continue to grow, we're confident that our new Redis architecture will keep pace—delivering the speed, reliability, and peace of mind our users expect. If you're facing similar challenges, don't hesitate to explore managed solutions and invest in robust migration practices. Your future self—and your customers—will thank you!

